Deep Dive into TEN Framework: Building Next-Generation AI Voice Applications
Introduction
In the rapidly evolving landscape of AI technology, voice interaction is emerging as the new paradigm for human-computer interaction. From OpenAI’s GPT-4o to Apple’s recently announced AirPods Pro 3, AI voice technology is transitioning from laboratories to everyday life. However, for developers, building a smooth, low-latency, real-time conversational voice AI application remains challenging.
Today, I want to take a deep dive into TEN Framework—a rapidly rising open-source project on GitHub—and explore how it solves the pain points in AI voice development and how we can leverage it to quickly build professional-grade voice AI applications.
TEN Framework at a Glance
TEN Framework is a professional Voice Agent engine that supports real-time conversations, allowing developers to quickly build an AI Agent capable of audio interaction in just minutes, creating your own AI voice applications from scratch.
As a technical framework, this project has garnered 7400+ stars and topped GitHub’s trending list within just one year of release. With rich use cases and a plugin ecosystem, it has become a mainstream AI voice framework.
GitHub: https://github.com/TEN-framework/TEN-framework
Among the framework’s many features, my favorite is the visual tool TMAN Designer, which provides a WYSIWYG experience—you can quickly build an AI voice robot just by dragging and dropping UI elements.
Technical Background: Why Voice AI Matters
1. Information Density Advantages
Voice interaction has natural advantages over text interaction in terms of information density:
-
Higher Efficiency: Speaking speed is typically 3-5 times faster than typing
-
Richer Information: Voice contains paralinguistic information like intonation, emotion, and emphasis
-
More Natural Interaction: Aligns with humans’ most primitive communication method
2. Broad Application Scenarios
-
Education: AI language tutors, pronunciation correction
-
Emotional Companionship: Virtual companions, psychological counseling
-
Productivity Tools: Voice assistants, meeting transcription
-
Cross-language Communication: Real-time translation, multilingual customer service
TEN Framework Core Technology Analysis
1. Architecture Design
TEN Framework adopts a modular plugin-based architecture, consisting of the following core components:
Plain Text TEN Framework Architecture ├── Core Engine │ ├── Event Loop │ ├── Message Queue │ └── Plugin Manager ├── Protocol Layer │ ├── WebRTC Support │ ├── WebSocket Support │ └── HTTP/REST API ├── Plugin System │ ├── STT Plugins (Speech-to-Text) │ ├── LLM Plugins (Large Language Models) │ ├── TTS Plugins (Text-to-Speech) │ └── Custom Plugins └── Tools ├── TMAN Designer (Visual Designer) └── CLI Tools
2. Key Technical Features
2.1 Ultra-Low Latency Implementation
TEN achieves industry-leading sub-second latency through the following technical approaches:
-
Stream Processing: Audio stream slicing for real-time conversion
-
Parallel Computing: Parallel processing of STT, LLM, and TTS stages
-
Intelligent Caching: Smart caching for high-frequency requests
-
Connection Pool Optimization: Connection reuse to reduce handshake time
2.2 Interruption Mechanism
Interruption in real conversations is crucial for natural interaction. TEN implements this through:
Python
Pseudocode example
class InterruptHandler: def init(self): self.current_stream = None self.vad_detector = VADDetector() # Voice Activity Detectiondef handle_audio_input(self, audio_chunk): if self.vad_detector.is_speech(audio_chunk): if self.current_stream: self.current_stream.interrupt() # Interrupt current output self.process_new_input(audio_chunk)
2.3 Multimodal Support
TEN supports not only voice but also integrates text, image, and other multimodal inputs/outputs:
-
Unified Interface Design: All modalities use a unified message format
-
Intelligent Routing: Automatic pipeline selection based on input type
-
Cross-modal Fusion: Supports scenarios like voice-describing images, image-to-voice generation
3. Plugin Ecosystem
TEN’s strength lies in its rich plugin ecosystem:
Supported Models and Services
Type Supported Services
STT Whisper, Azure Speech, Google Speech, iFlytek
LLM OpenAI, Claude, Gemini, DeepSeek, Qwen
TTS ElevenLabs, Azure TTS, Edge TTS, OpenAI TTS
Others Stable Diffusion, Midjourney API, Custom Models
Real-World Application Examples
Currently on GitHub, many developers have created practical AI demonstration cases based on TEN.
For example, by combining 3D digital avatars from Trulience avatars with TEN, you can create diverse AI intelligent voice assistants that allow direct conversations with digital humans.
Using text-to-image + voice models to create immersive audio storybooks.
In this process, we can discuss story content and scene images with AI through voice, allowing for more efficient content iteration.
Besides the cases mentioned above, there are many other exciting examples on the project’s GitHub page, such as computer application control, voice hardware robots, intelligent phone customer service, and more.
Hands-on: Building an Intelligent Voice Assistant
Environment Setup
First, let’s deploy the project. TEN comes with multiple installation methods. You can deploy locally with Docker for out-of-the-box functionality.
Considering different computer configurations and network stability, for demonstration purposes, I’ll use another simpler deployment method provided by TEN: GitHub Codespace.
GitHub Codespace cloud platform has many advantages: high efficiency, stable network, convenient deployment—perfect for beginners.
Let’s get started.
First, visit TEN’s GitHub project and create a new codespace:
https://github.com/TEN-framework/TEN-framework
Wait for environment initialization, and you’ll see an online VSCode editor with the TEN project code opened by default.
Before running TEN, we need some simple configuration.
Execute the command to copy the configuration file:
Bash cp ./.env.example .env
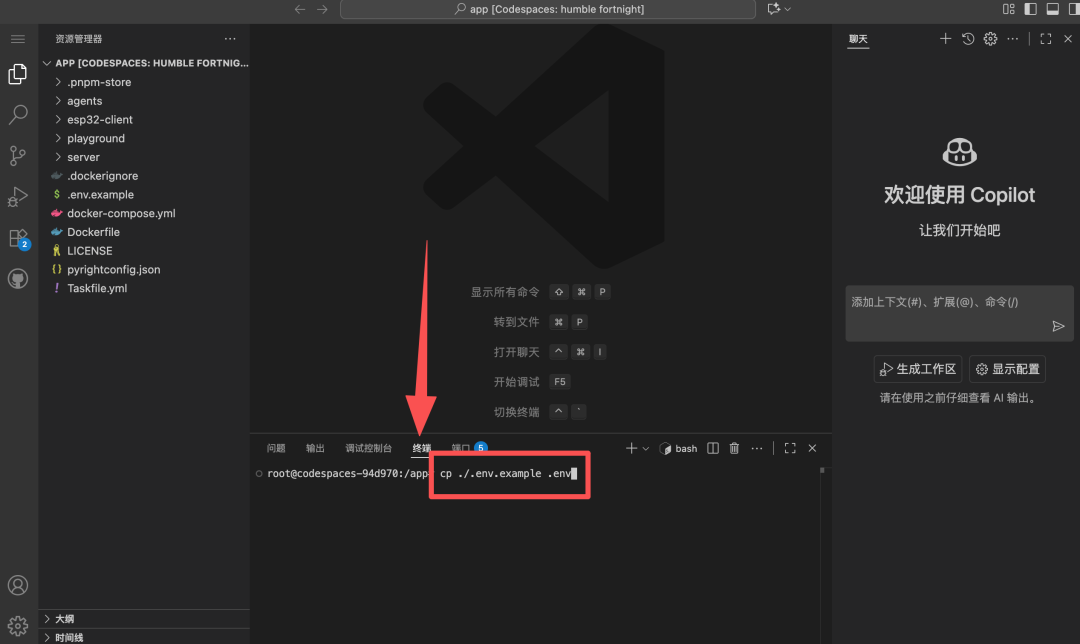
Fill in relevant API Keys in the .env file:
Use Agora for AI voice transmission
Use OpenAI models for text processing
Use Azure for text-to-speech
Configure the models you want based on your needs.
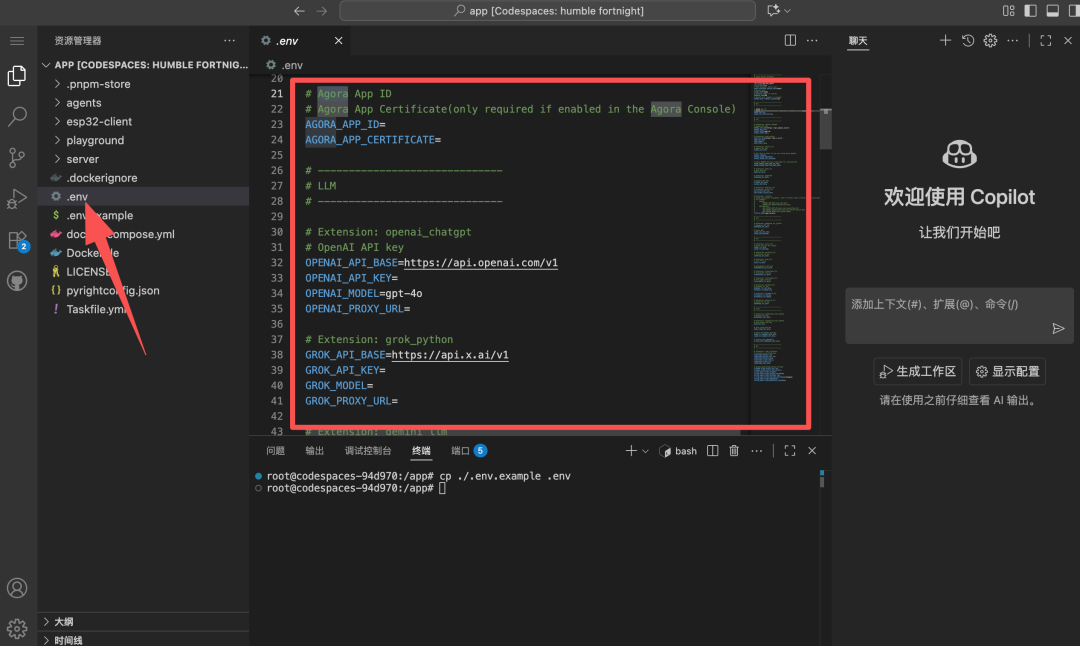
After filling in the keys, execute the following command to build the agent:
Bash task use
When you see the following output, the TEN Agent has been successfully built.

Now we can start the server:
Bash task run
After successful startup, the terminal will provide a server address. Access it in your browser:
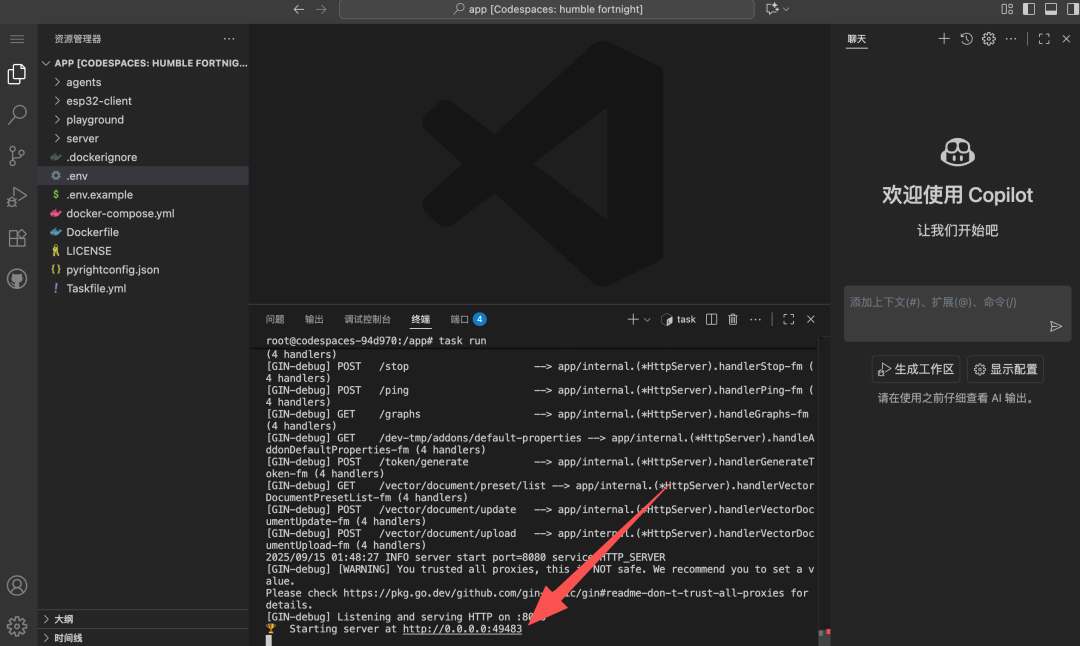
You’ll see the visual drag-and-drop TEN Agent workflow builder interface:
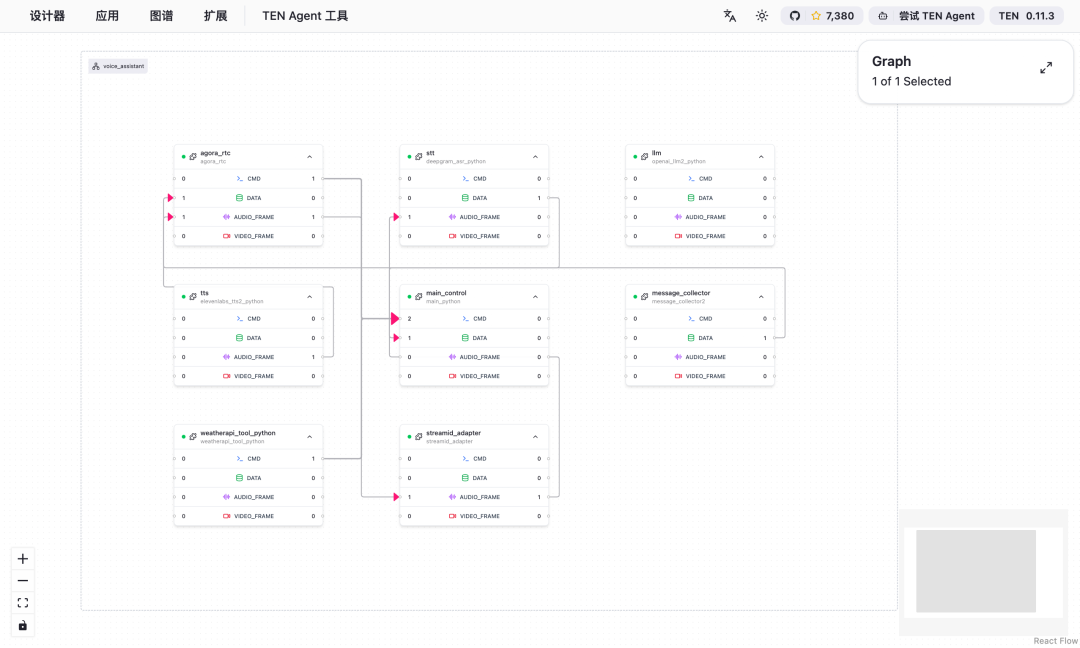
Here, you can freely configure LLM, TTS, STT, and various other models.
Right-click on a node and select “Update Properties” to configure model information:
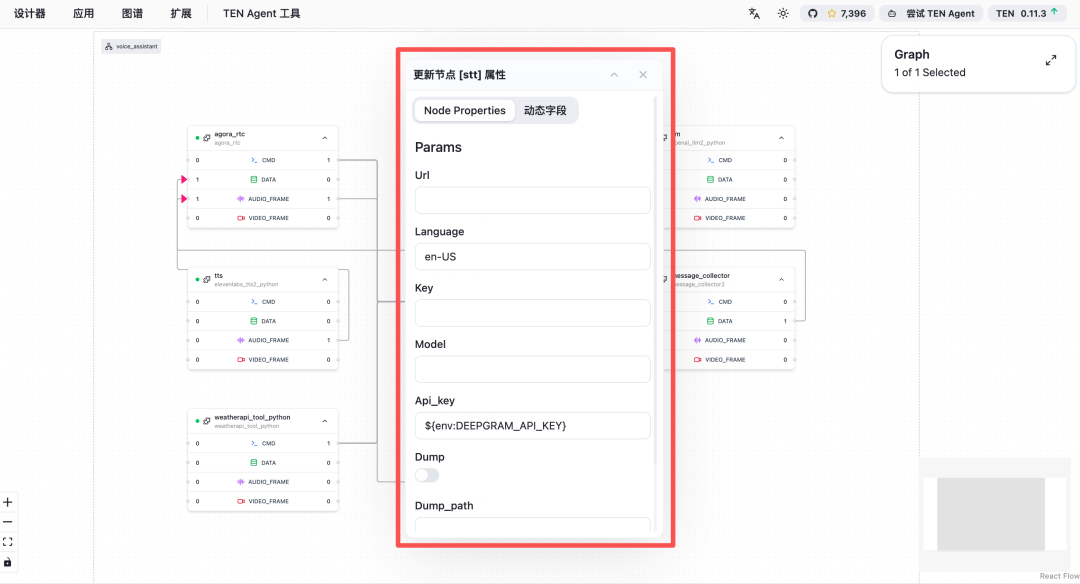
After configuration, right-click on the blank canvas, select “Manage Applications,” and click the “Run” icon:
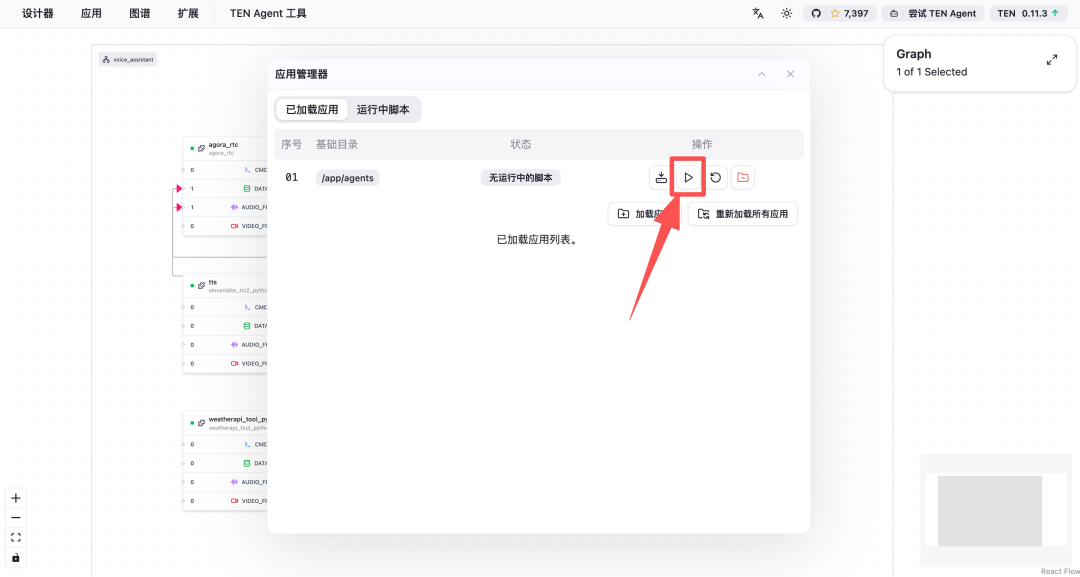
Then, check “Run with TEN Agent” option and click “Run” button:
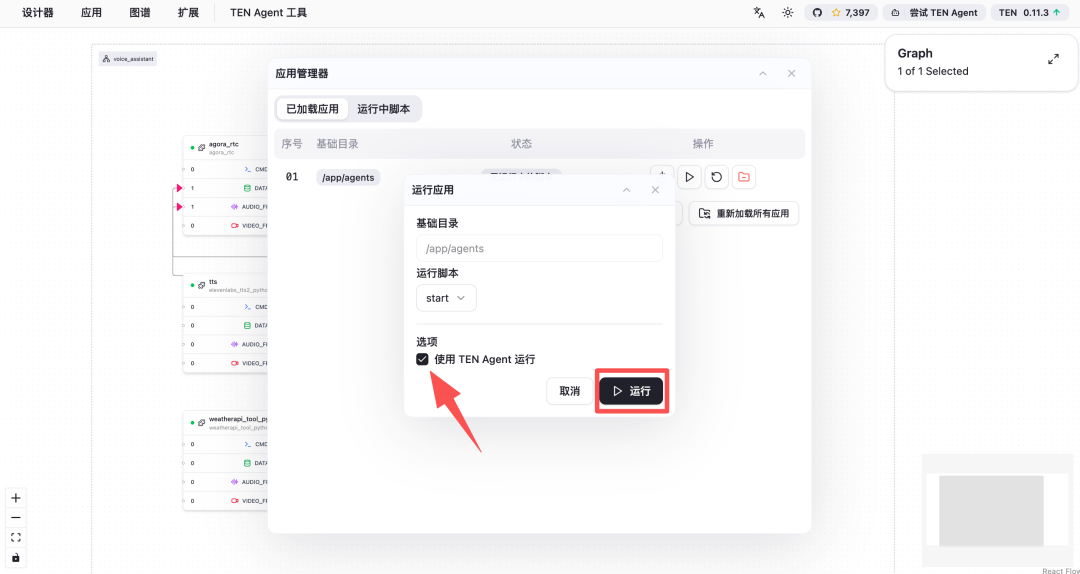
You can now test your first voice Agent application here.
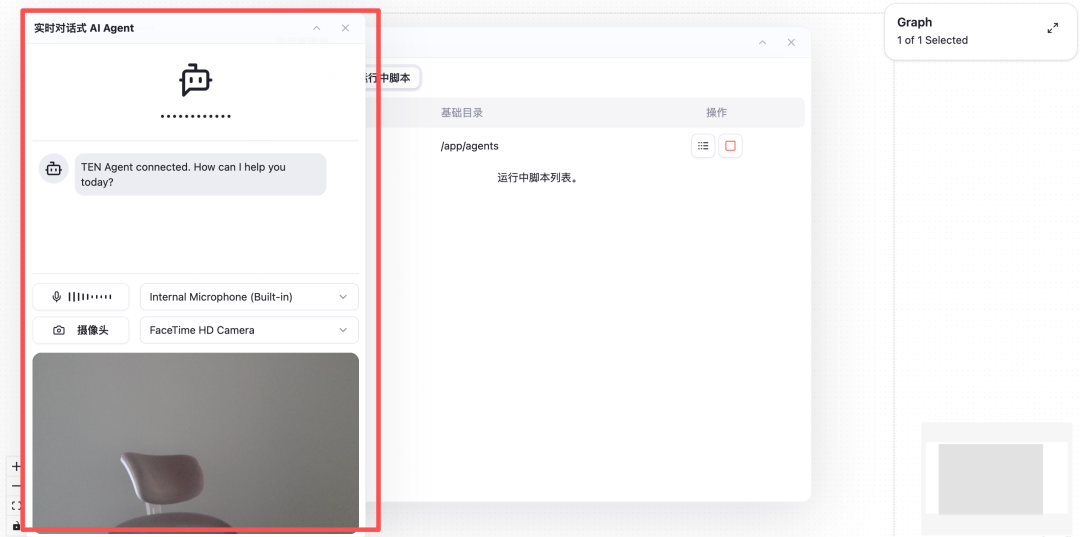
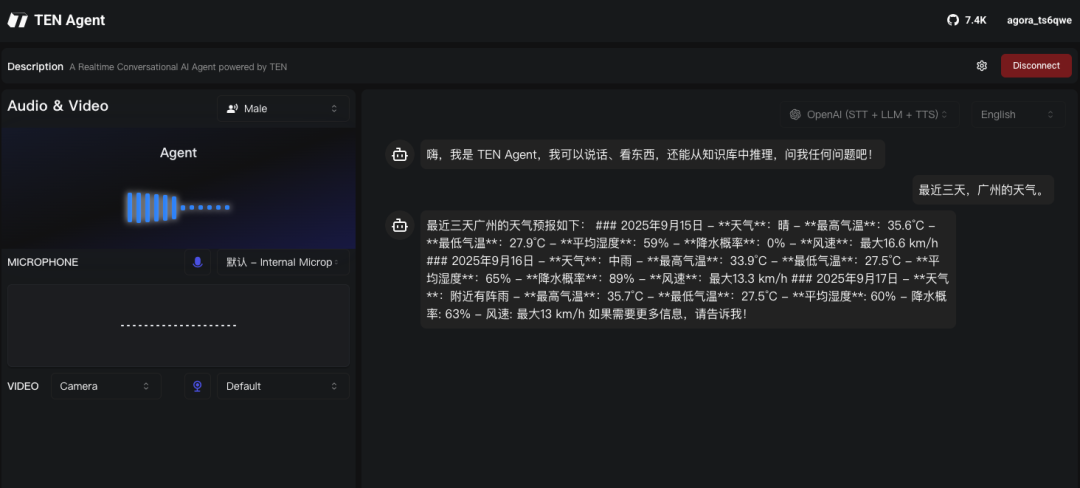
Through these simple steps, you can quickly build a real-time conversational AI Agent application.
You can also visit the official demo to experience the actual effects: https://agent.theTEN.ai
Performance Optimization Best Practices
1. Latency Optimization
-
Choose Appropriate Models: Balance between accuracy and speed
-
Use Edge Deployment: Deploy STT on edge nodes
-
Enable VAD: Use Voice Activity Detection to reduce unnecessary processing
2. Cost Optimization
-
Intelligent Routing: Select different models based on request complexity
-
Caching Strategy: Enable caching for common questions
-
Batch Processing: Combine multiple requests to reduce API calls
3. User Experience Optimization
JavaScript // Add thinking animation client.on(‘processing’, () => { showThinkingAnimation(); });// Implement progressive response client.on(‘partial_response’, (text) => { updateUIGradually(text); });// Error recovery mechanism client.on(‘error’, (error) => { fallbackToTextMode(); });
Integration and Compatibility
To adapt to various use scenarios, TEN supports all major global STT, LLM, and TTS providers including Deepseek, OpenAI, and Gemini. More importantly, TEN supports developers actively integrating their desired models—bring your own models. Developers can switch between models at any time during use.
For integration, TEN can quickly connect to Dify and Coze—just configure bot ID/API to make the robot speak. Or flexibly integrate into your products through MCP.
For compatibility, besides supporting all mainstream operating systems, TEN also supports programming languages and frameworks like C++/Go/Python/Node.JS.
Future Outlook
Technology Trends
-
Edge Deployment: More models will support local execution
-
Multilingual Mixing: Seamless switching between multiple languages
-
Emotion Computing: Recognizing and responding to user emotions
-
Personalized Customization: User habit-based adaptation
Application Prospects
Last week’s Apple product launch featured the first AirPods Pro 3 with AI translation capabilities, allowing users to communicate across languages barrier-free by wearing earphones. The product amazed everyone upon debut.
Sometimes you have to admire Apple’s influence. Although similar voice translation products existed in the market for the past two years, it wasn’t until these new earphones were unveiled that the public truly focused on the AI voice application market.
But I’ve always believed that earphones will become humanity’s first truly universal cyber equipment.
Beyond being lightweight and simple to interact with, more importantly, voice data processing is becoming increasingly efficient and standardized.
If large models can learn through massive voice information and then feed their capabilities back to users, the development prospects will be limitless.
In the foreseeable future, the explosion of various intelligent voice applications will drive the next round of AI technology development.
Conclusion
TEN Framework, introduced today, can be said to be an essential weapon for developers in the current AI wave.
It not only preemptively solves various problems that AI voice might face in actual development but also significantly lowers the learning curve through visual tools.
Additionally, from project installation and deployment, performance analysis, development testing, to specific interface usage, TEN provides very detailed documentation for reference.
On the path of developing AI voice applications, TEN has already paved the way for us. The next step is to boldly unleash your creativity and create freely.
I hope to have the honor of seeing your AI products come to life soon.
All the features and code mentioned above are open-sourced on GitHub. Interested students can check it out.


